BioPAL
BioPAL First AGB Tutorial#
The BIOMASS Product Algorithm Laboratory (BioPAL) hosts official tools for processing and analysing ESA’s BIOMASS mission data.
Website: www.biopal.org
Mailing: biopal@esa.int
Tutorial Objective#
In this tutorial, following topics will be discussed: - requirements, biopal installation and environment preparation for this notebook to work - setup and run of the Above Ground Biomass (AGB) processor (interactive notebook section) - usage of functionalities to read/plot input,intermediate and output products
Requirements#
The installation procedure described here makes use of the open-source package management system conda.
Python >=3.9
BioPAL from BioPAL distribution, or from PyPI release.
Installation and Jupyter Notebook Execution#
If BioPAL GitHub distribution is used (nothing to do here for using the PyPI release): Download and unzip the current BioPAL distribution (main branch) to your local hard drive (in alternative “GIT clone” the distribution: complete installation instructions can be found in README.md file).
Open a command window with conda available and follow this procedure.
Create an empty biopal environment: you can customize the biopal environment name:
conda create --name biopal python=3.9
Install GDAL library:
conda activate biopal
conda install -c conda-forge GDAL=3.5
Install Jupyter notebook
conda install -c conda-forge jupyterlab
Install the package (case of BioPAL from GitHub):
cd your_installation_folder/BioPAL/
pip install -e .
Install the package (case of PyPI release):
pip install biopal
Run Quick Start:
“FOLDER” is the path that will be filled with default and editable versions of Input_File.xml and Configuration_File.xml.
biopal-quickstart FOLDER
Open this Jupyter Notebook typing the following instructions:
cd yourInstallationFolder/BioPAL/doc/Notebooks
jupyter notebook
Setup AGB Processor#
Main Ingredients#
Main ingredients needed to run this tutorial:
Configuration_File.xml: is the BioPAL configuration file, generated with biopal-quickstart (this tutorial is focused on the AGB only)Input_File.xml: input file, generated with biopal-quickstart to be set by the user before running an instance of the processing
This Notebook is supposed to be executed from BioPAL/biopal/doc/Notebooks/BioPAL.ipynb.
Setup of the AGB processor includes: - Input File check / preparation - Configuration File check / preparation
BioPAL datasets#
BioPAL gives easy access to several datasets that are used for examples in the documentation and testing. These datasets are hosted on the MAAP and must be downloaded for use. Contact biopal@esa.int to receive access to the dataset and for more information. Each dataset is composed by two folders: - dataSet: folder containing L1 stacks of coregistered and calibrated SLC (Single Look Complex) data - auxiliary_data_pf: folder containing auxiliary products which are related to each
particular dataSet
Also a Lidar AGB - Reference map for validation, is present. In this tutorial the AGB map used for validation is from 10.1109/JSTARS.2018.2851606.
Prepare Input#
Open the Input_File.xml and focus on the following sections (some sections are already filled for this demo):
L2_product: specifies the algorithm to be run, here kept toAGBto enable the Above Ground Biomass processing (objective of this tutorial)output_specificationsection:output_folder: full path of the folder where processing will save the products. Each run will generate a new sub-folder tagged with the processing time stamp (only in case of single run of the complete suite, see later section)geographic_grid_sampling:value, in meters, of the sampling for the final processed product on geographic map, valid (east and north directions). Note: set this to50 [m]for this tutorial, for validation with the available Lidar AGB-Reference mapdataset_querysection:L1C_repository: should be put equal to one of thedataSetfolder described above (demo_lope_twoused here)L1C_datestart and stop values to select L1 products, in UTC format (do not modify default ones for this demo)auxiliary_products_folder: should be put equal to theauxiliary_data_pffolder described above (demo_lope_twoused here); in particular, the sub-folder ReferenceAGB, contains the reference data used to calibrate the AGB estimation inversion algorithmgeographic_boundaries_polygon: a set of 3 or more latitude-longitude points describing a polygon used to select L1 products (do not modify default ones for this demo)
Prepare Configuration#
The BioPAL configuration file is Configuration_File.xml and it is already filled with default AGB parameters to get valid estimation results; main parameters the users can modify are described hereafter, for more details refer to the complete documentation.
ground_cancellationsection:enhanced_forest_height: forest height in meters used in the processing to determine the vertical wavenumber for which the ground cancelled data is generated (only with more than two acquisitions)estimate_agbsection:number_of_tests: number of tests executed for AGB estimation following a random sampling scheme of estimation and calibration points (reference)fraction_of_roi_per_test: percentage of estimation points randomly selected for each testfraction_of_cal_per_test: percentage of calibration points randomly selected for each testintermediate_ground_averaging: ground cancelled averaging window size in meters on ground: it should be less or equal to product_resolution/2 (see below)product_resolution: output product resolution (AGB) in meters on geographic mapdistance_sampling_area: estimation points distance in meters on geographic mapestimation_valid_values_limits: validity range of the output product in t/ha, invalid values will be masked out
Run AGB Processor#
There are two ways to run the AGB processor: - execution of the “main” in a single run - manual execution of each specific AGB step
Note about python path: if the first step in following code does not work, you can manually set the biopal_path in the example, editing the string biopal_path = r”your_installation_path/BioPAL/biopal”
[1]:
from pathlib import Path
import sys
import os
import warnings
warnings.filterwarnings('ignore') # warnings silenced for convenience
# First try an import to verify if the python path alread contains biopal, otherwise do the import
try:
from biopal.__main__ import biomassL2_processor_run
print('The BioPAL is already into the python path')
except:
# manually add the biopal_path to the python path
biopal_path = r"your_installation_path/BioPAL/biopal"
sys.path.append( biopal_path )
# Try an import to verify the python path
try:
from biopal.__main__ import biomassL2_processor_run
print('The BioPAL path "{}" has been succesfully added to the python path'.format(biopal_path))
except Exception:
raise Exception( 'The BioPAL Notebook needs to be executed from the folder "BioPAL/doc/Notebooks" and the "biopal" environment should be enabled too. It has been executed from "{}" instead.'.format(notebook_working_dir) )
The BioPAL is already into the python path
Run AGB Processor by execution of each AGB step#
The AGB processor can be executed by manual run of each AGB step (APPs): each APP computes the inputs needed by the following one, and updates the input file adding each APP specific section, and (when needed) also the configuration file.
The first APP to be executed, the dataset_query, is in charge of getting from the L1C_repository only the stacks matching the specified temporal and geographical region of interest.
It takes as input the inputs\Input_File.xml path, prepared in the above steps of this tutorial.
The input file will be updated adding the new section stack_based_processing needed to the following APP. The updated input file will be saved into the output folder.
[4]:
# Edit the input pat with the folder containing the input file (see biopal-quickstart)
input_path = r"your_path_here/Input_File.xml"
from biopal.dataset_query.dataset_query import dataset_query
if not Path(input_path).exists():
raise ValueError('Path of Input_File not found, it should be set manually.')
# Initialize dataset query APP (no configuration file needed in this case)
dataset_query_obj = dataset_query()
# Run dataset query APP
print('Query started...')
input_path_from_query = dataset_query_obj.run( input_path )
print('The Input_File has been updated with the new section "stack_based_processing" and saved to {}'.format(input_path_from_query))
Query started...
Query completed.
The Input_File has been updated with the new section "stack_based_processing" and saved to C:\ARESYS_PROJ\workingDir\biopal_agb_tutorial\output2\InputFile_StackBasedProcessingAGB.xml
Hereafter we check the new stack_based_processing section added to the input file: as an example we print all the SLC SAR images acquisition IDs selected by the query and the path of the DTM projected in radar coordinates.
[4]:
from biopal.io.xml_io import parse_input_file
# read the updated input file:
input_params_obj = parse_input_file(input_path_from_query)
# get the new section stack_based_processing:
stack_based_processing_obj = input_params_obj.stack_based_processing
# read the IDs of the stacks found from the query:
found_stack_ids = stack_based_processing_obj.stack_composition.keys()
print('SLC SAR images (slant range geometry) stacks and acquisitions found from the query')
for stack_id, acquisition_ids in stack_based_processing_obj.stack_composition.items():
print('\n Stack:')
print(' ', stack_id)
print(' Acquisitions:')
for acq_id in acquisition_ids:
print(' ', acq_id)
dataSet_path = input_params_obj.dataset_query.L1C_repository
print('\n The above stacks with the acquisitions can be found at following path:\n {}'.format( dataSet_path ))
# Print the path of the DTM projected in radar coordinates
reference_height_path = Path.home().joinpath(
dataSet_path,
stack_based_processing_obj.reference_height_file_names[stack_id]
)
print('\n Full path of the reference height file valid for the above stack {}: \n {}'.format(stack_id, reference_height_path))
SLC SAR images (slant range geometry) stacks and acquisitions found from the query
Stack:
GC_02_H_230.00_RGSW_00_RGSBSW_00_AZSW_00
Acquisitions:
GC_02_H_230.00_RGSW_00_RGSBSW_00_AZSW_00_BSL_00
GC_02_H_230.00_RGSW_00_RGSBSW_00_AZSW_00_BSL_01
GC_02_H_230.00_RGSW_00_RGSBSW_00_AZSW_00_BSL_02
Stack:
GC_02_H_275.00_RGSW_00_RGSBSW_00_AZSW_00
Acquisitions:
GC_02_H_275.00_RGSW_00_RGSBSW_00_AZSW_00_BSL_00
GC_02_H_275.00_RGSW_00_RGSBSW_00_AZSW_00_BSL_01
GC_02_H_275.00_RGSW_00_RGSBSW_00_AZSW_00_BSL_02
The above stacks with the acquisitions can be found at following path:
C:\ARESYS_PROJ\workingDir\biopal_data_V2_update\demo_lope_two\dataSet
Full path of the reference height file valid for the above stack GC_02_H_275.00_RGSW_00_RGSBSW_00_AZSW_00:
C:\ARESYS_PROJ\workingDir\biopal_data_V2_update\demo_lope_two\auxiliary_data_pf\Geometry\ReferenceHeight\GC_02_H_275.00_RGSW_00_RGSBSW_00_AZSW_00
[9]:
# plots: input L1c products
import numpy as np
from matplotlib import pyplot as plt
from biopal.io.data_io import BiomassL1cRaster # read also "BiomassL1cRaster" class doc string: the class is to read
# biopal L1 slant range / azimuth data format
from biopal.utility.plot import * # BioPAL offers different optional pre built methods to plot BiomassL1cRaster objects:
# "plot", "plot_db", "plot_abs", "plot_angle", "plot_rad2deg".
# Plotting one of the SLC, also showing different ways to use the pre built plot methods, or manual plot
slc_path = Path.home().joinpath( dataSet_path, acq_id)
# initialize the SLC data object (its an L1C Raster)
slc_obj = BiomassL1cRaster(slc_path, channel_to_read=2) # (example: channel "2" is H/V)
# 1) Automatic plot with some custom inputs ("plot_db" example):
plot_db(slc_obj, title="SLC H/V [dB]", clims=[-40, 5]) # all optional inputs are: ax, title, clims, xlims, ylims
plt.show()
# 2) Automatic plot ("plot_abs" example)
plot_abs(slc_obj)
plt.show()
# 3) Passing a matplotlib.pyplot axis to the automatic plot, than customize the axis as desired ("plot_angle" example):
fig, ax = plt.subplots()
plot_angle(slc_obj, ax=ax)
ax.set_xlabel("my xlabel")
ax.set_ylabel("my ylabel")
ax.set_title("SLC H/V angle portion example [deg]")
ax.set_xlim([8, 10])
ax.set_ylim([6, 8])
fig.show()
# 4) Manual plot, from slc_obj attributes:
plt.figure()
plt.imshow(
10 * np.log10(np.abs(slc_obj.data) ** 2),
extent=[slc_obj.x_axis[0], slc_obj.x_axis[-1], slc_obj.y_axis[-1], slc_obj.y_axis[0],],
cmap="gray",
)
plt.xlabel(slc_obj.x_axis_description)
plt.ylabel(slc_obj.y_axis_description)
plt.title("SLC H/V [dB], manual example")
plt.show()
# From here on into this Notebook, automatic plot functions are used.
# Plotting the reference height
refheight_data_obj = BiomassL1cRaster(reference_height_path) # channel not specified, first (the only one) is read here.
plot(refheight_data_obj, title='DTM [m]') # we chose a standard plot with the method "plot"
plt.show()
print('Level 1 data')



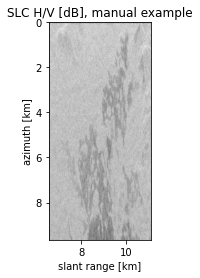

Level 1 data
The second APP to be executed, is the StackBasedProcessingAGB, which takes the above stacks and preprocesses them with ground cancellation and geocoding.
It takes as input: - the Input File path, the one prepared by the dataset_query APP, containing the new stack_based_processing section - the Configuration File path
The input file will be updated in the end adding the new section core_processing_agbfor the following APP. The configuration file is updated too. The updated input file and configuration file will be saved into output folder.
[6]:
# Edit the input pat with the folder containing the configuration file (see biopal-quickstart)
configuration_file_path = r"your_path_here/Configuration_File.xml"
from biopal.agb.main_AGB import StackBasedProcessingAGB
if not Path(configuration_file_path).exists():
raise ValueError('Path of Configuration File not found, it should be set manually.')
# Initialize Stack Based Processing AGB APP
stack_based_processing_obj = StackBasedProcessingAGB( configuration_file_path )
# Run Stack Based Processing AGB APP
print('AGB stack-based processing APP started...')
input_file_from_stack_based, configuration_file_updated = stack_based_processing_obj.run( input_path_from_query )
print('The Input_File has been updated with the new section "core_processing_agb" and saved to {}'.format(input_file_from_stack_based))
AGB stack-based processing APP started...
AGB stack-based processing APP ended correctly.
The Input_File has been updated with the new section "core_processing_agb" and saved to C:\bio\outNotebook\Input_File_CoreProcessingAGB.xml
Hereafter we print the paths of some of the computed data, all stored in the output folder.
[10]:
# Some of the computed output paths:
import os
input_params_obj = parse_input_file(input_file_from_stack_based)
output_folder = input_params_obj.output_specification.output_folder
npy_name = str(list(Path( Path.home().joinpath(output_folder, 'Products', 'breakpoints') ).rglob('*.npy'))[0])
ground_canc_sr_path = Path.home().joinpath(
output_folder,
npy_name,
)
print('\n Path of ground cancelled data in slant range geometry: \n {}'.format(ground_canc_sr_path))
geocoded_dir = str(list(Path( Path.home().joinpath(output_folder, 'Products', 'temp', 'geocoded') ).rglob('GC_*'))[0])
sigma_tif_name = str(list(Path( geocoded_dir ).rglob('sigma_nought_VH.tif'))[0])
ground_canc_gr_path = Path.home().joinpath(
geocoded_dir,
sigma_tif_name,
)
print('\n Path of ground cancelled VH data, geocoded: \n {}'.format(ground_canc_gr_path))
theta_tif_name = str(list(Path( geocoded_dir ).rglob('theta.tif'))[0])
theta_inc_path = Path.home().joinpath(
geocoded_dir,
theta_tif_name,
)
print('\n Path of incidence angle map, geocoded: \n {}'.format(theta_inc_path))
Path of ground cancelled data in slant range geometry:
C:\bio\outNotebook\AGB\Products\breakpoints\ground_cancelled_SR_GC_02_H_230.00_RGSW_00_RGSBSW_00_AZSW_00.npy
Path of ground cancelled VH data, geocoded:
C:\bio\outNotebook\AGB\Products\temp\geocoded\GC_02_H_230.00_RGSW_00_RGSBSW_00_AZSW_00\sigma0_vh.tif
Path of incidence angle map, geocoded:
C:\bio\outNotebook\AGB\Products\temp\geocoded\GC_02_H_230.00_RGSW_00_RGSBSW_00_AZSW_00\theta.tif
[11]:
# plots: intermediate products (from output "Products/temp/" folder)
from biopal.io.data_io import BiomassL2Raster # read also "BiomassL2Raster" class doc string; the class is to read:
# BioPAL L2 geocoded east-north output products tif data (default behavior, see after in this tutorial)
# BioPAL intermediate geocoded lat-lon tif data (by setting intermediate_latlon_flag to True, this case)
# ground cancelled geocoded, in dB
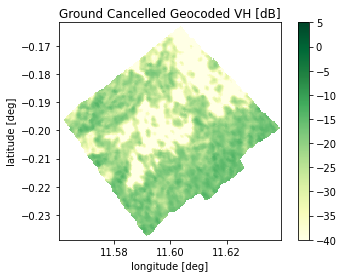
GC_GR_VH_obj = BiomassL2Raster(str(ground_canc_gr_path), band_to_read=1, intermediate_latlon_flag=True)
plot_db(GC_GR_VH_obj, title='Ground Cancelled Geocoded VH [dB]', clims=[-40,5])
plt.show()
# Incidence angle map, in degrees (this it is saved to "Products/temp" in radiants)
theta_inc_obj = BiomassL2Raster(str(theta_inc_path), band_to_read=1, intermediate_latlon_flag=True)
plot_rad2deg(theta_inc_obj, title='Incidence Angle [deg]')
plt.show()
# or, in radiants, just use "plot":
# plot(theta_inc_obj, title='Incidence Angle [rad]')
# plt.show()
# the following is Products/breakpoints "python npy" product; no specific method is available for reading/plotting:
# to be done manually
# ground cancelled slant range:
GC_SR_VH = np.load( str(ground_canc_sr_path), allow_pickle=True).item(0)['VH']
GC_SR_VH_db = 10*np.log10( np.abs( GC_SR_VH )**2 )
# for the axis
azimuth_pixel_spacing = 3.63676 # got from xml
slant_range_pixel_spacing = 11.988876 # got from xml
samples, lines = GC_SR_VH_db.shape
range_length_km = samples*slant_range_pixel_spacing/1000
azimuth_length_km = lines*azimuth_pixel_spacing /1000
# Plot
plt.figure(3)
plt.imshow( GC_SR_VH_db, interpolation='none', origin='upper', cmap='gray',
extent=[ 0, range_length_km, azimuth_length_km, 0] )
plt.colorbar()
plt.clim([-40,5])
plt.xlabel('slant range [km]')
plt.ylabel('azimuth [km]')
plt.title('Ground Cancelled Slant Range VH [dB]')

[11]:
Text(0.5, 1.0, 'Ground Cancelled Slant Range VH [dB]')

The third and last APP to be executed is CoreProcessingAGB, which is in charge of performing the AGB estimation.
It takes as input: - the Input File path, the one prepared by the stack_based_processing APP, containingh the new core_processing_agb section - the Configuration File path, the one updated by the stack_based_processing APP
[12]:
from biopal.agb.main_AGB import CoreProcessingAGB
# Initialize Core Processing AGB APP
agb_processing_obj = CoreProcessingAGB( configuration_file_updated )
# Run Main APP #2: AGB Core Processing
print('AGB core-processing APP started (this will take some time, wait for ending message)...')
agb_processing_obj.run(input_file_from_stack_based)
AGB core-processing APP started (this will take some time, wait for ending message)...
WARNING:root:AGB: limit units for parameter agb_1_est_db and associated observable agb_1_cal_db do not match (db_t/ha and t/ha). However, this could still be OK: the observable source unit is t/ha and transform is db. Proceed with caution.
WARNING:root:AGB: skipping formula terms: 1, 2, 3 due to lack of useful data for observables: agb_1_cal_db.
WARNING:root:AGB: skipping formula terms: 1, 2, 3 due to lack of useful data for observables: agb_1_cal_db.
WARNING:root:AGB: skipping formula terms: 1, 2, 3 due to lack of useful data for observables: agb_1_cal_db.
WARNING:root:AGB: skipping formula terms: 1, 2, 3 due to lack of useful data for observables: agb_1_cal_db.
AGB core-processing APP ended correctly.
Hereafter we print the paths of the final product and the calibration product used in the algorithm. Products are geocoded to EQUI7 map
[13]:
# Final products full paths:
input_params_obj = parse_input_file(input_file_from_stack_based)
output_folder = input_params_obj.output_specification.output_folder
tile_equi7_folder = list(Path.home().joinpath( Path(output_folder), 'Products','global_AGB').rglob('*'))[0]
tile_equi7_subfolder = list(Path(tile_equi7_folder).rglob('*'))[0]
final_estimation_path = list(Path(tile_equi7_subfolder).rglob('*.tif'))[0]
print('\n Path of the final AGB estimation product, in EQUI7 map geometry: \n {}'.format(final_estimation_path))
reference_agb_folder = input_params_obj.stack_based_processing.reference_agb_folder
calibration_path = Path.home().joinpath(
reference_agb_folder, 'cal_05_no_errors.tif')
print('\n Path of the input calibration data used: \n {}'.format(calibration_path))
Path of the final AGB estimation product, in EQUI7 map geometry:
C:\bio\outNotebook\AGB\Products\global_AGB\AF050M\E045N048T3\agb_1_est_db_backtransf_.tif
Path of the input calibration data used:
C:\ARESYS_PROJ\workingDir\biopal_data_V2_update\demo_lope_two\auxiliary_data_pf\ReferenceAGB\cal_05_no_errors.tif
[19]:
# plots: output L2 products
# BioPAL L2 geocoded east-north output products tif data can be read with BiomassL2Raster
from scipy.signal import convolve
# pyplot axis limits (east and north, km, for the EQUI7 tile)
east_lims = [4509, 4522] # east, km
north_lims = [5032, 5044] # north, km
# lidar AGB - Reference map for validation
# (set your path here before run this block, can be found is part of the BioPAL datasets)
lidar_agb_path = r"your_path_here/lope_lidar/equi7_50m/lidar_agb/EQUI7_AF050M/E045N048T3/lidar_AGB_AF050M_E045N048T3.tif"
if not Path(lidar_agb_path).exists():
raise ValueError('Path of Lidar AGB - Reference map for validation should be set manually')
lidar_agb_obj = BiomassL2Raster( lidar_agb_path, band_to_read=1)
plot(lidar_agb_obj, title='Lidar AGB [t/ha]', clims=[0,600], xlims=east_lims, ylims=north_lims)
plt.show()
# Calibration AGB (patch from full Lidar map as reference data)
calibration_path = str( Path.home().joinpath( reference_agb_folder, 'cal_05_no_errors.tif') )
cal_agb_obj = BiomassL2Raster( calibration_path, band_to_read=1)
plot(cal_agb_obj, title='Calibration Area AGB [t/ha]', clims=[0,600])
plt.show()
# Estimated AGB, with east-north plot limits, to show only the estimation zone from the whole EQUI7 tail
est_agb_obj = BiomassL2Raster( str( final_estimation_path ), band_to_read=1)
plot(est_agb_obj, title='Estimated AGB [t/ha]', clims=[0,600], xlims=east_lims, ylims=north_lims)
plt.show()
# Data analysis
# Histogram Lidar vs Estimated AGB
NumBins = 50
histogram_range_tha = [0,500]
histogram_plot_limits = [0,70]
#### prepare the lidar and estimated AGB for the histogram ###
# (filtering at approximately 200 m both to bring Lidar map at same resolution as estimated map)
x_ax = est_agb_obj.x_axis*1000 # axis in the objects are in [km], setting to [m]
y_ax = est_agb_obj.y_axis*1000
DX = np.abs( x_ax[1]-x_ax[0] )
filLen_x = np.int( np.floor( 200/DX/2 ) *2 +1 )
step_x = np.int( np.floor( filLen_x-1)/2 )
DY = np.abs( y_ax[1]-y_ax[0] )
filLen_y = np.int( np.floor( 200/DY/2 ) *2 +1 )
step_y = np.int( np.floor( filLen_y-1)/2 )
NumRows = lidar_agb_obj.data.shape[0]
NumCols = lidar_agb_obj.data.shape[1]
for rowIdx in np.arange(NumRows):
lidar_agb_obj.data[rowIdx,:]= convolve(lidar_agb_obj.data[rowIdx,:], np.ones(filLen_x)/(filLen_x), method='direct', mode='same')
for colIdx in np.arange(NumCols):
lidar_agb_obj.data[:,colIdx]= convolve(lidar_agb_obj.data[:,colIdx], np.ones(filLen_y)/(filLen_y), method='direct', mode='same')
for rowIdx in np.arange(NumRows):
est_agb_obj.data[rowIdx,:]= convolve(est_agb_obj.data[rowIdx,:], np.ones(filLen_x)/(filLen_x), method='direct', mode='same')
for colIdx in np.arange(NumCols):
est_agb_obj.data[:,colIdx]= convolve(est_agb_obj.data[:,colIdx], np.ones(filLen_y)/(filLen_y), method='direct', mode='same')
############################################
# remove all NaN data from vectors
lidar_agb_vec = lidar_agb_obj.data.flatten()
estimated_agb_vec = est_agb_obj.data.flatten()
if lidar_agb_vec.shape == estimated_agb_vec.shape:
idxNotNan = np.where(~np.isnan(lidar_agb_vec) * ~np.isnan(estimated_agb_vec))
lidar_agb_vec = lidar_agb_vec[idxNotNan]
estimated_agb_vec = estimated_agb_vec [idxNotNan]
# Histogram generation and plot
H, xedges, yedges = np.histogram2d( lidar_agb_vec, estimated_agb_vec, NumBins)
plt.figure(9)
plt.imshow(H,
interpolation='none',
cmap='gray',
extent=[ histogram_range_tha[0], histogram_range_tha[1], histogram_range_tha[1], histogram_range_tha[0]] ,
vmin=histogram_plot_limits[0], vmax=histogram_plot_limits[1],
aspect='auto')
plt.gca().invert_yaxis()
maxVal = np.int( np.min( [np.max(lidar_agb_vec), np.max(estimated_agb_vec)]) )
minVal = np.int( np.max( [np.min(lidar_agb_vec), np.min(estimated_agb_vec)]) )
Xline = np.arange(histogram_range_tha[0],histogram_range_tha[1])
Yline = Xline;
plt.plot(Xline, Yline, 'r')
plt.margins(x=0)
plt.xlabel('Estimated biomass [t/ha]')
plt.ylabel('Lidar biomass [t/ha]')
else:
print('Skipping validation with provided lidar AGB - Reference map: the geographic_grid_sampling in input file should be set to 50 [m] ')
print('Processing results')


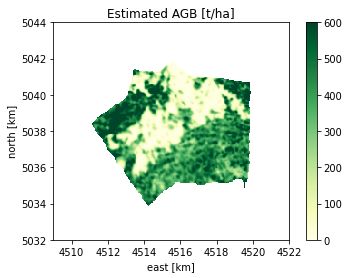
Processing results

Run AGB Processor, complete#
The following code will run the complete AGB processor, by calling the biomassL2_processor_run function, which automatically call the APPs in sequence.
It takes as input: - the path of the Input_File.xml - the folder containing the Configuration_File.xml
[3]:
from biopal.__main__ import biomassL2_processor_run
input_path = r"your_path_here/Input_File.xml"
configuration_folder = r"your_path_here"
# run the AGB processor
biomassL2_processor_run( input_path, configuration_folder )
Query completed.
AGB stack-based processing APP ended correctly.
WARNING:root:AGB: limit units for parameter agb_1_est_db and associated observable agb_1_cal_db do not match (db_t/ha and t/ha). However, this could still be OK: the observable source unit is t/ha and transform is db. Proceed with caution.
WARNING:root:AGB: skipping formula terms: 1, 2, 3 due to lack of useful data for observables: agb_1_cal_db.
WARNING:root:AGB: skipping formula terms: 1, 2, 3 due to lack of useful data for observables: agb_1_cal_db.
WARNING:root:AGB: skipping formula terms: 1, 2, 3 due to lack of useful data for observables: agb_1_cal_db.
WARNING:root:AGB: skipping formula terms: 1, 2, 3 due to lack of useful data for observables: agb_1_cal_db.
AGB core-processing APP ended correctly.
[3]:
True